O que está acontecendo
Dados de treino contaminados incluem quatro categorias distintas: dados com viés histórico (decisões discriminatórias do passado usadas para treinar o futuro), dados desatualizados (padrões de comportamento de período não representativo), dados incompletos (sub-representação de grupos relevantes), e dados com erros de rotulagem (decisões incorretas do passado tratadas como verdade).
O modelo não distingue dado bom de dado ruim. Aprende o padrão que existe — qualquer que seja ele.
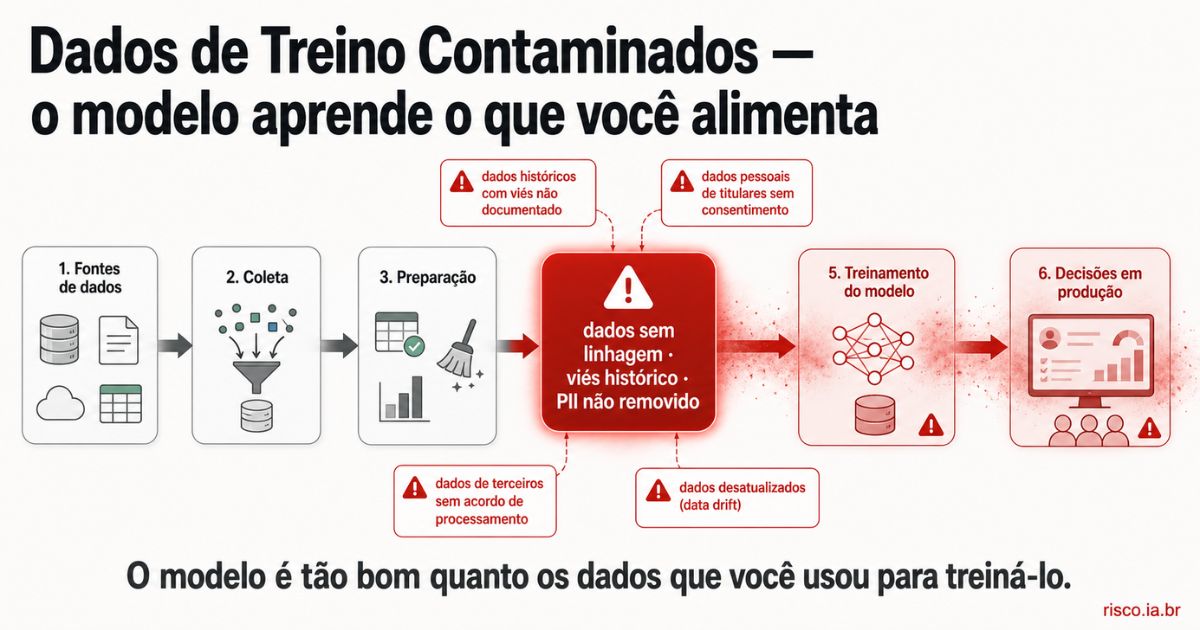
A escala é o problema adicional: um decisor humano com viés afeta um caso por vez. Um modelo com viés afeta milhares de decisões por dia.
Por que isso é problema do CFO
Modelo de crédito treinado com histórico de discriminação vai discriminar de forma sistemática e escalável. A empresa vai responder por isso — não a equipe de dados que construiu o modelo.
Para o EU AI Act, sistemas de alto risco com viés em dados de treino são proibidos. Para a LGPD, discriminação algorítmica viola o princípio de não discriminação do Art. 6º.
O risco não é intencional — é estrutural. Isso não atenua a responsabilidade legal.
O que acontece quando isso vai para auditoria
Auditores vão perguntar: qual é a origem dos dados de treino? Por qual período? Foi feita análise de viés antes do go-live? Se a resposta for "não foi feita análise de viés", você tem achado — independente de o modelo estar discriminando ou não.
Ausência de análise de viés documentada é, em si, um controle inexistente. Você não pode provar que o modelo não discrimina se nunca testou.
Impacto financeiro estimado
Litígio coletivo por discriminação algorítmica: valores variam. Casos nos EUA e Europa indicam exposição de dezenas a centenas de milhões. No Brasil, ainda em desenvolvimento, mas a base legal existe.
Multa ANPD por violação do princípio de não discriminação: até 2% do faturamento, limitado a R$ 50 milhões.
Custo de remediação: re-treinamento com dados limpos + nova validação + auditoria de conformidade. Estimativa: R$ 300k a R$ 1,5M dependendo da complexidade do modelo.
O que fazer
- Documentar a origem de todos os dados usados no treinamento: base, período, como foram coletados, quem os aprovou
- Antes do go-live: fazer análise de disparate impact — existem ferramentas open source (IBM AI Fairness 360, por exemplo)
- Testar distribuição de resultados por grupos demográficos relevantes para o contexto do modelo
- Estabelecer limiar aceitável de disparidade — "zero disparidade" não é realista, mas "disparidade dentro de X%" é defensável
- Rever dados de treino a cada ciclo de revalidação do modelo — padrões históricos mudam
"Você não pode provar que o modelo não discrimina se nunca testou. E ausência de teste é evidência de ausência de controle."